


Most network automation projects don’t fail because the tooling is bad.
They fail because teams automate the wrong things, in the wrong order, for the wrong reasons.
The problem isn’t what we automate.
It’s what we trust.
The Old Automation Mental Model Is Broken
Traditional automation thinking goes like this:
If a task is repetitive, automate it.
If it’s slow, script it.
If it’s error-prone, remove the human.
That logic works in clean, well-defined systems.
Production networks are none of those things.
Networks are stateful, inconsistent, and full of historical baggage.
Automation amplifies whatever discipline already exists—and punishes whatever doesn’t.
The Automations That Actually Work
Some automations consistently survive contact with production.
They share one trait: they reduce uncertainty instead of increasing blast radius.
1. Configuration Standardization (Not Blind Pushing)
Automating configuration generation works.
Automating configuration deployment without validation doesn’t.
Good automation:
- Builds configs from a source of truth
- Enforces structure and intent
- Refuses to deploy when inputs are incomplete
Bad automation:
- Pushes deltas blindly
- Assumes the network matches documentation
- Optimizes for speed over correctness
Standardization beats speed every time.
 2. Drift Detection, Not Drift Correction
2. Drift Detection, Not Drift Correction
Detecting configuration drift is one of the highest-ROI automations you can build.
Automatically fixing drift is one of the fastest ways to cause outages.
Drift detection:
- Surfaces risk early
- Creates engineering conversations
- Preserves human judgment
Drift correction:
- Hides complexity
- Masks intent mismatches
- Breaks things quietly
Seeing the problem is more valuable than “fixing” it automatically.
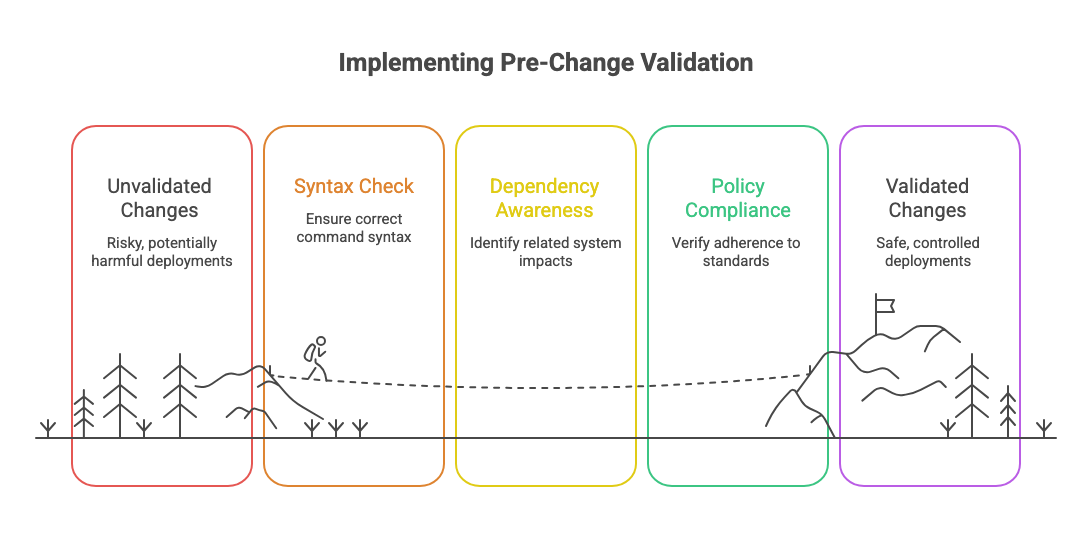
 3. Pre-Change Validation
3. Pre-Change Validation
This is where most automation projects should start—and rarely do.
Validating that a change can be applied safely is far more valuable than applying it quickly.
Effective validation checks:
- Syntax correctness
- Dependency awareness
- Policy compliance
- Impact radius
Automation that stops bad changes is more valuable than automation that deploys good ones.
 4. Safe Provisioning With Hard Boundaries
4. Safe Provisioning With Hard Boundaries
Provisioning automation works when:
- Device roles are strict
- Templates are boring
- Inputs are validated
It fails when:
- Every device is “special”
- Exceptions creep into templates
- Humans override guardrails “just this once”
Provisioning should feel restrictive.
If it feels flexible, it’s already broken.
5. Backups and State Capture
This one is boring—and that’s why it works.
Automated backups:
- Reduce panic during incidents
- Enable comparison and forensics
- Support rollback decisions
The mistake teams make is treating backups as insurance instead of data.
Backups are not for restoration.
They’re for understanding what changed.
The Automations That Usually Backfire
Some use cases look attractive and fail repeatedly.
- Fully autonomous remediation
- Blind “self-healing” workflows
- Real-time config correction based on alerts
- Automated incident response without context
These fail because networks don’t operate on single signals.
They operate on tradeoffs.
When automation acts without understanding intent, humans lose control—and trust evaporates.
The Hidden Cost of “Successful” Automation
Even working automation has side effects:
- Engineers lose muscle memory
- Understanding decays
- Debugging gets harder
This doesn’t mean automation is bad.
It means it must be paired with visibility, review, and accountability.
Automation should make engineers more confident, not less involved.
 Final Thought
Final Thought
Network automation isn’t about doing more things automatically.
It’s about deciding which decisions should never be automated.
The strongest automation programs are conservative by design.
They validate more than they act.
They stop changes more often than they push them.
Automation doesn’t create control.
Discipline does—and automation only works when it enforces it.