

Today’s networks evolve so quickly that traditional change windows can’t keep up. Relying manual configuration means extra costs in terms of outages, inconsistencies, and wasted engineering hours—a “manual tax.” By adopting CI/CD (Continuous Integration / Continuous Delivery) for networking, you streamline your processes with consistent pipelines: propose changes, test them, validate, deploy, and verify. This method brings the reliable workflow of software development to managing devices, templates, and policies.
Why CI/CD for networking is different (and doable)
Networking pipelines must address considerations such as stateful infrastructure, out-of-band risk, and vendor diversity. These factors do not hinder CI/CD implementation; instead, they influence its development and approach.
- Stateful: devices keep config and counters — so we test intended state (golden configs, policies) before we touch actual state.
- Risk: a single line can blackhole traffic — so we stack guardrails: linting, policy checks, pre-change diffs, approvals, staged rollout, auto-rollback.
- Diversity: multi-vendor is normal — so we abstract with data models, templates, and libraries (Ansible, Nornir, Terraform, NAPALM, Genie, NSO).
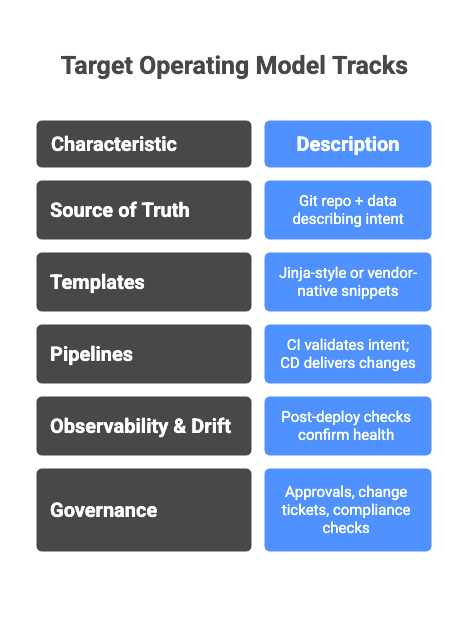
The target operating model
Think in tracks:
- Source of Truth (SoT): Git repo + data (YAML/JSON/CSV/DB) describing intent (VRFs, VLANs, QoS classes, peers).
- Templates: Jinja-style or vendor-native snippets, versioned alongside data.
- Pipelines: CI validates intent; CD delivers changes progressively (lab → staging → prod).
- Observability & Drift: post-deploy checks confirm health and catch drift; deviations open issues automatically.
- Governance: approvals, change tickets, and compliance checks embedded in the pipeline.
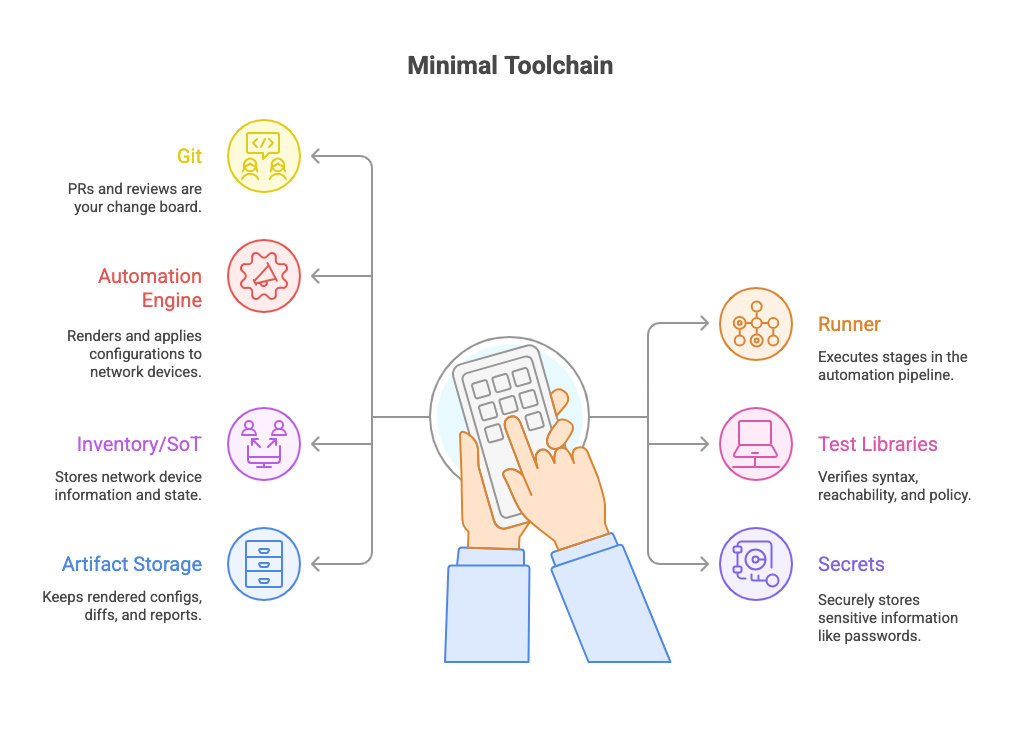
 Minimal toolchain that works
Minimal toolchain that works
- Git (GitHub/GitLab/Bitbucket) — PRs and reviews are your change board.
- Runner (GitHub Actions / GitLab CI / Jenkins) — executes stages.
- Automation engine (Ansible, Nornir, or Terraform) — renders and applies configurations.
- Ansible and Nornir excel at device-level automation (CLI, API, SSH).
- Terraform fits when managing network infrastructure as code — cloud interconnects, BGP peers, firewalls, SD-WAN fabrics, or network services with APIs (ACI, NSO, Catalyst Center, Meraki, F5, FortiManager, etc.).
- Combine them: Terraform for provisioning and dependencies, Ansible/Nornir for configuration and state enforcement.
- Test libraries (pyATS/Genie, Batfish, nornir-netmiko tests) — syntax, reachability, policy verification.
- Inventory/SoT (simple YAML → NetBox later) — start small, level up.
- Secrets (Vault, GitHub/GitLab secrets) — no creds in repos.
- Artifact storage — keep rendered configs, diffs, and reports.
 The pipeline, stage by stage
The pipeline, stage by stage
1) Trigger & intake
A pull request (PR) with template/data changes kicks things off. Labels or paths decide scope: which devices, tenants, or sites. Auto-assign reviewers. Block PRs with failing checks.
2) Lint & static checks (fast feedback)
- Lint templates (Jinja) and data (YAML schemas).
- Enforce conventions (hostname rules, ASN ranges, IPAM boundaries).
- Fail on secrets in diff.
Result: you catch typos and policy violations in seconds, not during a 2am window.
3) Render and don’t deploy (safe preview)
Render device configs as artifacts. Post side-by-side diffs back to the PR: current vs intended per device, with added/removed lines highlighted. Reviewers see the exact change blast radius.
4) Pre-change tests (prove it works before you touch prod)
Pick a testing stack that fits your team:
- Batfish: model reachability/ACL/ECMP changes offline.
- pyATS/Genie: parse “show” outputs from lab/staging to assert state.
- Custom Nornir tests: check BGP neighbor counts, NTP sync, interface states.
5) Staged delivery (small blast radius first)
On merge, the CD job gates by environment:
- Lab (always): push to a virtual or hardware lab first.
- Staging (select sites): limited scope, out of path when possible.
- Production: orchestrate by batches with health checks between batches.
Use maintenance windows and rate limiting (e.g., 10 devices per wave). If health checks fail, halt and roll back the current batch only.
6) Post-deploy verification (prove “done”)
Run assertions after each batch:
- Control plane: BGP/OSPF neighbors, LSDB size, route counts.
- Data plane: a few traceroutes/pings across critical paths.
- Platform health: CPU, memory, linecard status, TCAM usage.
Write clear pass/fail to the job log and attach parsed reports.
7) Drift watch & continuous compliance
Nightly job pulls running-config → normalizes → compares with intended.
- If drift appears, open an issue with the diff and device tag.
- Optionally auto-correct low-risk drift (banner, SNMP, NTP) in “enforce mode.”
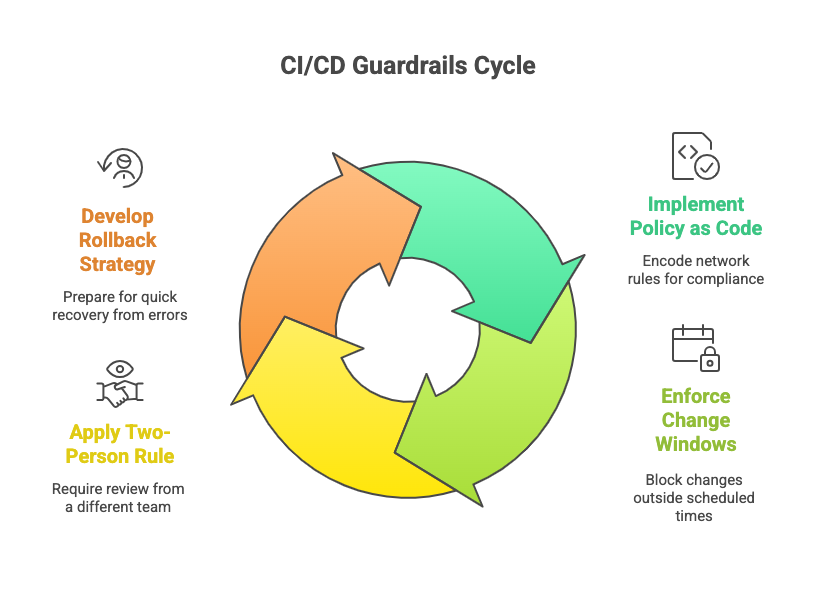
Guardrails that save you
- Policy as code: encode rules like “no /0 accepted from edges,” “QoS AF4x only on uplinks,” “no VLAN 1 active.” Use custom validators or OPA/Rego if your team has it.
- Change windows as code: pipeline checks the calendar (simple JSON/ICS) to block outside windows unless labeled “Emergency.”
- Two-person rule: PR must have one reviewer from a different team or on-call rotation.
- Rollback strategy: generate no … lines or revert commits. Keep last-known-good artifacts per device.
 A tiny starter workflow (readable, vendor-agnostic)
A tiny starter workflow (readable, vendor-agnostic)
Below is a condensed GitHub Actions-style flow. Same logic maps to GitLab or Jenkins.
on: pull_request: paths: ["data/**", "templates/**"] push: branches: ["main"] paths: ["data/**", "templates/**"] jobs: validate: runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Lint & schema-check run: make lint schema # yamllint, jsonschema, jinja-lint - name: Render configs run: make render # outputs ./artifacts/rendered/ - name: Pre-change diff run: make diff # posts PR comment with per-device diffs deploy: if: github.ref == 'refs/heads/main' needs: validate runs-on: ubuntu-latest steps: - uses: actions/checkout@v4 - name: Stage: LAB run: make deploy ENV=lab BATCH=all && make verify ENV=lab - name: Stage: STAGING (canary) run: make deploy ENV=staging BATCH=canary && make verify ENV=staging - name: Stage: PROD (waves) run: | make deploy ENV=prod BATCH=wave1 && make verify ENV=prod make deploy ENV=prod BATCH=wave2 && make verify ENV=prod
Your make targets call Ansible, Nornir, or Terraform modules depending on what’s being deployed. Secrets live in Actions Secrets or Vault. Artifacts (rendered configs, diffs, test reports) are uploaded per run.
Data modeling and templates that scale
- Start with device-role folders (core, dist, edge) and site variables (VLANs, subnets, peers).
- Keep defaults for common services (NTP, AAA, syslog, SNMP, CoPP).
- Encode options (e.g., VXLAN EVPN vs. classic L3 core) as data flags rather than branching templates everywhere.
- For multi-vendor, map a single intent (e.g., “QoS class: AF41 for video”) to device-specific templates.
Security and safety
- No credentials in repos; rotate device creds quarterly.
- Per-environment accounts with least privilege (read-only for validate, config for prod stages).
- Out-of-band access documented in artifacts to recover from failed pushes.
- Encrypted logs if they contain diffs with sensitive IPs.
What to measure (so you know it’s working)
- Lead time: PR opened → prod deployed.
- Change failure rate: % of changes that require rollback.
- MTTR: time to detect and fix a failed change.
- Drift: number of devices out of intent per day.
- Manual touches: count of console sessions outside the pipeline.
Rollout plan you can execute this month
- Pick one low-risk domain (NTP/SNMP/AAA banners).
- Stand up the validate job and PR diffs; don’t deploy yet.
- Add lab deploy + verify; run it for a week.
- Move to staging canaries with auto-halt on failed verify.
- Define prod waves for a small site group.
- Expand coverage to routing policy, QoS, and interface profiles.
Implementing CI/CD does not eliminate all risks; rather, it ensures they are predictable and subject to inspection. This approach reduces time spent responding to unforeseen issues caused by changes and allows greater focus on architectural improvement. Begin with small steps, standardize existing practices, and allow your pipeline to develop alongside your network.
At MZS Networks, we assist organizations in modernizing their infrastructure, automating network operations, and building scalable systems that adapt to evolving business needs.
Disclaimer
The content and examples presented in this article are intended solely for educational and informational purposes. It is strongly recommended that network automation and CI/CD practices be thoroughly tested in controlled environments prior to implementation in production systems. MZS Networks disclaims any responsibility for operational impacts or outages that may arise from the use or misuse of the information contained herein.