


Manual network operations don’t usually fail loudly.
They rot quietly.
Configs drift. Engineers stop trusting what’s running. Changes get delayed because no one is fully sure what will break. Eventually, someone pastes the wrong block into the wrong device and the outage finally makes the problem visible.
That’s usually when automation enters the conversation.
Not as a strategy.
As a reaction.
The Real Problem Isn’t Scale. It’s Control.
Most teams don’t automate because the network is “too big.”
They automate because the network has become unknowable.
You no longer trust that:
- Devices are configured the same way
- Rollbacks are predictable
- What’s in Git matches what’s live
Automation looks like the fix. Push configs faster. Enforce consistency. Remove humans from the loop.
That instinct is understandable—and dangerous.
Because automation doesn’t fix broken operations.
It amplifies them.
 Why Automation Fails in Real Networks
Why Automation Fails in Real Networks
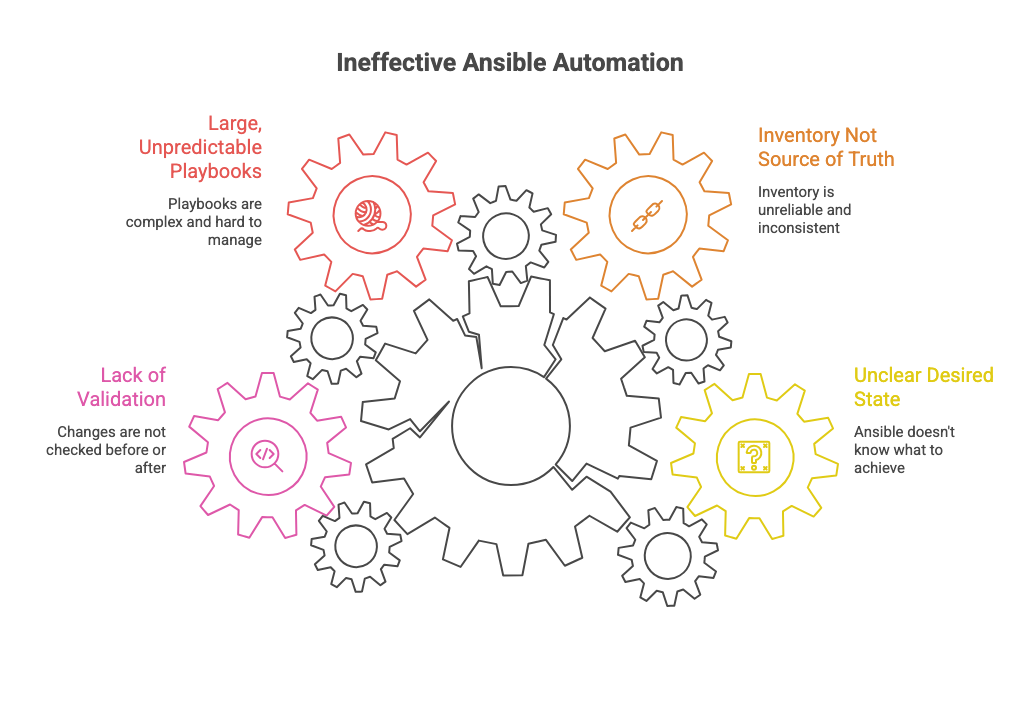
When Ansible “doesn’t work,” it’s rarely Ansible.
It’s usually one of these:
- Inventories that don’t reflect reality
- Playbooks that assume the happy path
- No validation of current state before changes
- No guardrails on blast radius
- No clear definition of what “correct” means
Teams automate the push, but not the thinking.
They skip:
- State validation
- Pre-checks
- Post-change verification
- Failure handling
The result is faster configuration drift instead of slower drift.
What Ansible Actually Is (When Used Correctly)
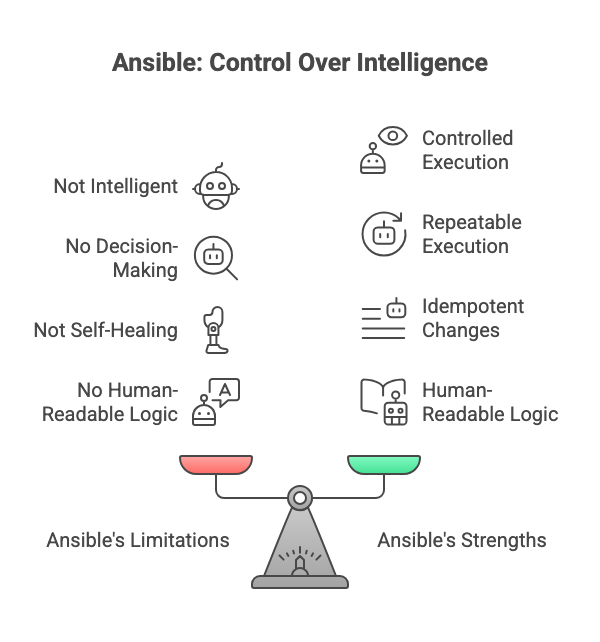
Ansible is not intelligence.
It’s not decision-making.
It’s not self-healing.
It’s a controlled execution engine.
Its real value is boring:
- Declarative intent
- Repeatable execution
- Idempotent changes
- Human-readable logic
That’s it.
And that’s enough—if the operational model is sound.
Where Ansible Shines
Ansible works best when:
- The desired state is clearly defined
- The inventory is treated as a source of truth, not a suggestion
- Playbooks are small, scoped, and predictable
- Changes are validated before and after execution
In that environment, Ansible becomes a force multiplier:
- Config drift becomes visible
- Changes become reviewable
- Rollbacks become mechanical
- Knowledge moves out of people’s heads and into code
Not faster chaos.
Slower, safer change.
 YAML, Playbooks, and the Trap of “Easy”
YAML, Playbooks, and the Trap of “Easy”
YAML’s readability is a double-edged sword.
It lowers the barrier to entry—but also lowers the barrier to bad automation.
Readable does not mean safe.
Simple does not mean correct.
A short playbook can still:
- Touch hundreds of devices
- Change routing behavior
- Break production traffic
The danger isn’t complexity.
The danger is underestimating impact.
Automation as an Operational Mirror
The first thing Ansible exposes is not efficiency.
It exposes:
- Inconsistent configs
- Undefined standards
- Missing documentation
- Fragile processes
This is why early automation efforts feel painful.
They surface problems that were previously hidden by manual work.
That pain is the point.
What Mature Teams Do Differently
Teams that succeed with Ansible:
- Treat playbooks like production code
- Review changes before execution
- Test against labs or subsets first
- Limit blast radius by design
- Accept that not everything should be automated
They don’t chase “full automation.”
They chase controlled change.
Final Thought
Ansible doesn’t make networks reliable.
Engineers do.
Ansible just removes excuses.
Used with discipline, it restores control.
Used blindly, it just makes outages faster.
Automation is not maturity.
Judgment is.
And Ansible only works when it serves that.